什么是mmap?
mmap 是一种用于将文件或设备与进程的地址空间关联起来的内存映射技术。通过 mmap,可以将文件的内容直接映射到进程的虚拟内存地址空间,使得文件的内容可以像操作普通内存一样进行读取和写入。
在Linux中,虚拟内存的布局如下:
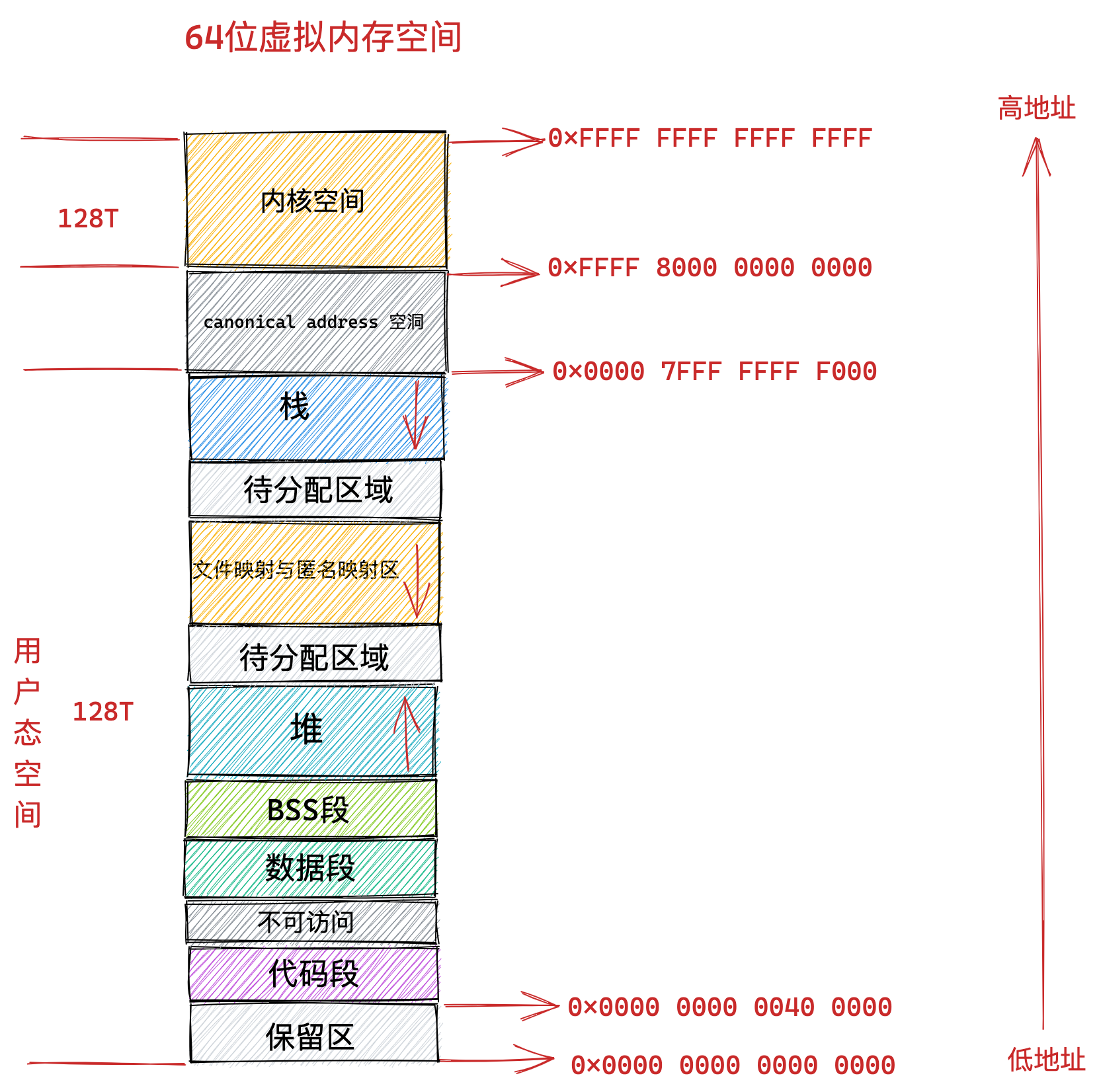
图片来源:小林coding
当我们在Linux上使用mmap系统调用时,得到的文件映射就会放在图中的“文件映射与匿名映射区”。每当我们需要读取或修改文件时,只需要去操作这一块虚拟内存即可,而省去了将文件的内容从磁盘读取到内核缓冲区,然后再拷贝到用户空间的缓冲区,这大大减小了资源开销。
系统调用参数说明
该lab希望我们实现xv6上的mmap和munmap系统调用,其函数声明为:
1
2
| void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t len);
|
这与Linux上的使用是相同的,对其中的参数解释如下:
void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);:
addr (void *):
- 这是建议的映射起始地址。通常设置为
NULL,由内核自动选择合适的地址。如果指定了非空地址,则内核尽量在这个地址处创建映射(但不保证)。(xv6中不要求实现,addr只要考虑为0/NULL的情况)
- 如果使用了
MAP_FIXED 标志,则必须将映射建立在 addr 所指向的地址,否则映射会失败。(xv6中不要求实现)
len (size_t):
- 要映射的内存长度(以字节为单位)。如果不是页大小的倍数,通常会向上舍入到最近的页边界。
prot (int):
- 映射区域的保护权限。可以是以下权限的组合:
PROT_READ: 映射区域可读。PROT_WRITE: 映射区域可写。PROT_EXEC: 映射区域可执行。PROT_NONE: 映射区域不可访问。
flags (int):
- 控制映射对象的类型、映射页是否可共享、映射是否同步到磁盘等。常见的标志有:
MAP_SHARED: 共享映射,对映射区域的修改会同步到底层文件,其他映射到同一文件的进程也会看到修改。MAP_PRIVATE: 私有映射,对映射区域的修改不会影响底层文件,修改是写时复制的(Copy-On-Write)。MAP_ANONYMOUS: 创建一个匿名映射,与文件无关。fd 参数被忽略,通常与 MAP_PRIVATE 结合使用。(xv6不要求实现)
fd (int):
- 打开的文件描述符,表示要映射的文件。如果使用
MAP_ANONYMOUS 标志,则此参数被忽略,通常设为 -1。
offset (off_t):
- 文件映射的起始偏移量。必须是页大小的整数倍。(xv6中不要求实现,即只要输入0)
int munmap(void *addr, size_t len):
addr (void *):
- 要解除映射的起始地址。这个地址必须是由之前的
mmap 调用返回的地址,或者是由 mmap 创建的某个映射区域的地址。
len (size_t):
- 要解除映射的内存长度,必须与
mmap 调用中的 len 相匹配。如果长度小于 mmap 时指定的长度,可能会导致部分映射区域仍然保留。
如何实现?
在xv6的虚拟内存布局中,可以看到堆区和trapframe之间有一片没有使用的区域,我们可以拿它作为文件映射区域。(xv6和Linux的虚拟内存布局有点区别,xv6的堆区在栈区上面)

当使用mmap系统调用时,也可以使用懒分配的策略(类似于Copy On Write):我们在mmap系统调用中 标识(不是分配) 文件映射区中有一个区域与文件相关联,但这时还不会分配物理块,自然还不急着将文件读入这片内存区域;当我们需要访问这片区域的内存时,可以通过触发page fault来分配物理块,然后读入文件内容到内存块中,并将虚拟内存映射到这块物理内存上。
使用munmap系统调用时,会解除文件在映射区[addr, addr + len]范围内的映射,将这块区域的内存写回文件,并释放掉这块内存。实验中保证释放的区域大小一定是页的整数倍。
我们也仿照Linux上的,让文件映射区从高地址处开始向低地址增长。下图是文件映射的样子,左边为映射区域大小不固定,右边为映射大小为页框的整数倍:

在实验的提示中,有说到mmaptest中没有使用的功能可以不实现,其中每次使用mmap都是映射的PGSIZE的整数倍,那也就说明我们可以之用考虑右边的情况,这让实验降低了一点复杂度。
标识映射区域
根据实验提示,我们需要为每个进程设置用于标识映射区域的结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#define NVMA 16
struct vma {
uint len;
uint prot;
struct file *file;
int used;
int flags;
int offset;
uint64 start;
uint64 end;
};
struct proc {
...
struct vma vmas[NVMA];
};
|
实现sys_mmap
在此之前,我们需要先注册mmap和munmap系统调用,这里我们就不赘述了
获得映射区中的可用区域
什么意思呢?我们的映射区设计的是从高地址向低地址增长,那么我们每次需要增长时,最简单的就是在已有的映射区中找到地址最低的,并将新的映射区放在其之后,即地址最低的映射区的start就是新的映射区的end:

可是这样的算法有很大的问题:如果我们取消了文件2的映射后,有一个只需要一个页框的映射区,按照这个算法它会被安排到文件3的映射区下面,这样就浪费了之前释放的映射区。
不过嘛,在这个实验中这么做没什么问题😜,如果想知道更好的方法,可以参考这篇博客。
我的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
static uint64 vma_end() {
struct proc *p = myproc();
struct vma *v = 0;
uint64 min_vma_end = TRAPFRAME;
for (int i = 0; i < NVMA; i++) {
if (p->vmas[i].used && p->vmas[i].end <= min_vma_end) {
min_vma_end = p->vmas[i].end;
v = &p->vmas[i];
}
}
if (!v) {
return min_vma_end;
}
return PGROUNDDOWN(v->start);
}
|
sys_mmap
虽然刚刚我们有了可以获取映射区地址的函数,但是这个系统调用并不用真正分配内存,它只需要进行标记vma即可。
- 找到一个可以使用的vma区域的end地址
- 初始化vma
- 返回vma的start地址
这里我觉得最重要的就是设置start和end地址,一个映射区的范围为[start, end),其长度就为len,通过vma_end函数我们可以获取新映射区的end地址,再通过end - len即可得到start地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
uint64 sys_mmap(void) {
uint64 addr;
int len, prot, flags, fd, offset;
struct proc *p = myproc();
struct file *f;
argaddr(0, &addr);
argint(1, &len);
argint(2, &prot);
argint(3, &flags);
argfd(4, &fd, &f);
argint(5, &offset);
if (addr < 0 || len < 0 || prot < 0 || flags < 0 || fd < 0 || offset < 0) {
return -1;
}
if (!f->readable && (prot & PROT_READ) && (flags & MAP_SHARED)) {
return -1;
}
if (!f->writable && (prot & PROT_WRITE) && (flags & MAP_SHARED)) {
return -1;
}
struct vma *v = 0;
for (int i = 0; i < NVMA; i++) {
if (p->vmas[i].used == 0) {
v = &p->vmas[i];
break;
}
}
if (!v) {
return -1;
}
uint64 end = vma_end();
v->len = len;
v->prot = prot;
v->file = f;
v->used = 1;
v->flags = flags;
v->offset = offset;
v->end = end;
v->start = end - len;
filedup(f);
return v->start;
}
|
懒分配策略
- 找到触发fault的地址,并据此找到对应的vma
- 校验
- 分配物理内存块
- 设置权限
- 读取文件内容到内存块中,注意偏移量
- 设置物理内存与虚拟内存的映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
static int handle_mmap_fault(uint64 addr) {
struct proc *p = myproc();
struct vma *v = 0;
for (int i = 0; i < NVMA; i++) {
if (p->vmas[i].used && addr >= p->vmas[i].start && addr < p->vmas[i].end) {
v = &p->vmas[i];
break;
}
}
if (!v) {
printf("no no no\n");
return -1;
}
if (!v->file->readable && r_scause() == 13 && (v->flags & MAP_SHARED)) {
return -1;
}
if (!v->file->writable && r_scause() == 15 && (v->flags & MAP_SHARED)) {
return -1;
}
uint perm = PTE_V | PTE_U;
if (v->prot & PROT_READ) {
perm |= PTE_R;
}
if (v->prot & PROT_WRITE) {
perm |= PTE_W;
}
if (v->prot & PROT_EXEC) {
perm |= PTE_X;
}
char *pa = kalloc();
if (!pa) {
return -1;
}
memset(pa, 0, PGSIZE);
uint offset = addr - v->start;
ilock(v->file->ip);
if (readi(v->file->ip, 0, (uint64)pa, offset, PGSIZE) == 0) {
iunlock(v->file->ip);
return -1;
}
iunlock(v->file->ip);
mappages(p->pagetable, PGROUNDDOWN(addr), PGSIZE, (uint64)pa, perm);
return 0;
}
|
然后在usertrap中处理读写造成的page fault:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
void
usertrap(void)
{
...
if(r_scause() == 8){
...
} else if((which_dev = devintr()) != 0){
} else if (r_scause() == 13 || r_scause() == 15) {
if (handle_mmap_fault(r_stval()) != 0) {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
setkilled(p);
}
} else {
...
}
..
}
|
实现sys_munmap
sys_munmap
sys_munmap需要将内存块中的内容写回文件,并释放这个内存块。这里我们将这个操作额外封装一层,即不将具体实现放在sys_munmap中,这是因为在进程销毁也需要使用这个操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
uint64 sys_munmap(void) {
uint64 addr;
int len;
argaddr(0, &addr);
argint(1, &len);
if (addr < 0 || len < 0) {
return -1;
}
return munmap(addr, len);
}
|
解除映射
- 遍历所有的vma,找到addr所在的vma,要求addr不能是vma区域的中间位置,可以是开头和结束位置。
- 使用
mmap_writeback将这addr的内容写回对应的文件
- 更新vma的范围
- 如果vma的len小于等于0,说明该文件的映射已经结束,可以关闭文件了,同时这个vma也应该释放了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
uint64 munmap(uint64 addr, int len) {
struct proc *p = myproc();
struct vma *v = 0;
for (int i = 0; i < NVMA; i++) {
if (p->vmas[i].used && addr >= p->vmas[i].start && addr < p->vmas[i].end) {
v = &p->vmas[i];
break;
}
}
if (!v) {
return -1;
}
if (addr > v->start && addr + len < v->end) {
return -1;
}
mmap_writeback(p->pagetable, addr, len, v);
if (addr == v->start) {
v->start += len;
} else if (addr == v->end - len) {
v->end = addr;
}
v->len -= len;
if (v->len <= 0) {
fileclose(v->file);
v->used = 0;
}
return 0;
}
|
将映射区内容写回文件
- 遍历这个vma中的所有页框,对于其中的每一个页帧,获取对应的pte,需要考虑到由于懒分配带来的影响。
- 如果这个页帧被修改过,并且这块vma的策略是可写,那么就将这个页写回文件,注意偏移量
- 释放这块页帧对应的物理内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
static int mmap_writeback(pagetable_t pgtbl, uint64 src_va, int len, struct vma *vma) {
pte_t *pte;
uint64 addr;
for (addr = PGROUNDDOWN(src_va); addr < PGROUNDDOWN(src_va + len); addr += PGSIZE) {
if ((pte = walk(pgtbl, addr, 0)) == 0) {
panic("mmap_writeback");
}
if (!(*pte & PTE_V)) {
continue;
}
if ((*pte & PTE_D) && (vma->flags & MAP_SHARED)) {
begin_op();
ilock(vma->file->ip);
uint offset = addr - src_va;
writei(vma->file->ip, 1, addr, offset, PGSIZE);
iunlock(vma->file->ip);
end_op();
}
kfree((void *)PTE2PA(*pte));
*pte = 0;
}
return 0;
}
|
我们使用到了pte中的一个标志位PTE_D,它是用来标识一个页框是否被修改了(即脏位),我们需要在riscv.h中定义它:
1
2
3
|
#define PTE_D (1L << 7)
|
在exit时需要清空映射区
当进程退出时,其映射区中的内容也需要释放,这也是为什么要将munmap独立出来的原因。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
void
exit(int status)
{
struct proc *p = myproc();
if(p == initproc)
panic("init exiting");
for (int i = 0; i < NVMA; i++) {
if (p->vmas[i].used) {
if (munmap(p->vmas[i].start, p->vmas[i].len) != 0) {
panic("exit: munmap");
}
}
}
...
}
|
在fork时需要“复制”映射区
我们这里所说的复制并不是将映射区的内存块在fork时都复制给子进程,可别忘了COW哦,我们只需要复制父进程中的vma数组,知道映射的哪些位置有什么样的文件映射,在真正访问时再按需加载即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
int
fork(void)
{
...
for (int i = 0; i < NVMA; i++) {
if (p->vmas[i].used) {
np->vmas[i] = p->vmas[i];
filedup(p->vmas[i].file);
}
}
...
}
|
Code Details
代码实现详情请见:Github
Reference
- https://xiaolincoding.com/os/3_memory/linux_mem.html#_3-%E8%BF%9B%E7%A8%8B%E8%99%9A%E6%8B%9F%E5%86%85%E5%AD%98%E7%A9%BA%E9%97%B4
- https://ttzytt.com/2022/08/xv6_lab11_record/index.html
Summary
这个lab的代码还是比较多的,不过它还给我们放了些水,只让我们实现一些基础的功能。在lab中更重要的是要搞清楚mmap的实现原理,一定要去理解其中的细节。